
One of the main obstacles to the widespread adoption of machine learning in business is the compromise between interpretability and complexity of the algorithm. The more complex the internal structure of the model, the deeper the relationships between variables it can find, but also the more difficult it becomes for people to understand, especially those not directly connected with the world of machine learning and statistics.
The most banal example of a simple model is linear regression. Each linear regression coefficient shows how the predicted value will change on average if the value of the variable increases by one unit.
For example, Figure 1 demonstrates the simplest model for predicting the number of days of overdue repayment of a loan with one variable — the age of the client. According to this model, increasing the age of the client by one year on average reduces the forecast for delay by 0.36 days.
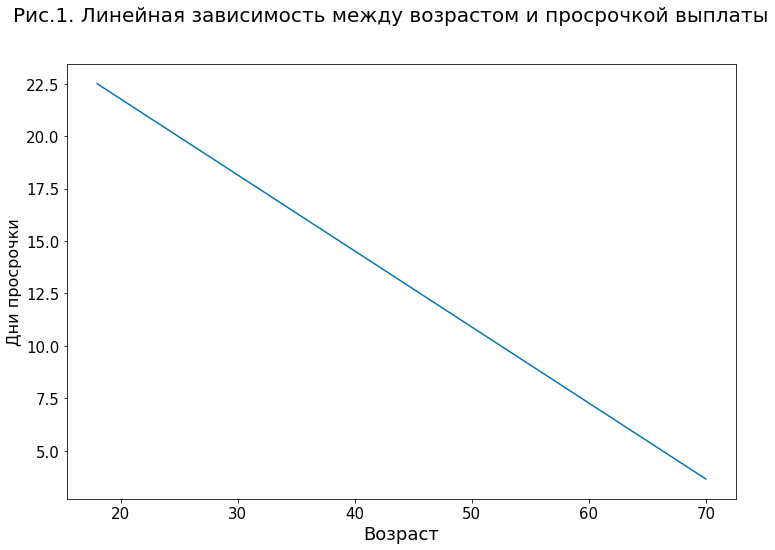
However, even with linear models, not everything is so simple. For example, if there are several highly correlated variables in the model (for example, the age and number of closed loans in the credit history), direct interpretation of the coefficients for these variables may not be such a trivial task. The situation is even more complicated with nonlinear models, where the dependencies between variables and prediction can have a complex, non-monotonic form with many interdependencies.
Such models in machine learning are often called “black boxes” (black box). A set of variables is fed to the input of the model, on the basis of which it calculates its prediction, but how exactly this decision was made, what factors influenced it — the answers to these questions often remain hidden in the “black box” of the algorithm.
Before proceeding to the description of existing interpretation methods, it would be useful to discuss what exactly is meant by the interpretability of the model and why it is necessary to interpret and explain the predictions of ML models in general.
What is interpretability?
The term “interpretability of the model” is umbrella, that is, it includes a whole set of features and definitions.
In the most general form, interpretability can be defined as the degree to which a person can understand the reason why a certain decision was made (for example, the decision to issue a loan to a client).
This definition is a good starting point, but it does not answer many important questions. For example, who exactly is meant by a “person” — an expert in this subject area or an ordinary person “from the street”? What factors should be taken into account when assessing interpretability — the time and mental resources spent, the depth of understanding of the internal processes of models, the person’s trust in them?
Despite the lack of a unified approach to this concept at the moment, we intuitively feel what makes the ML model more or less interpretable. This is any information in a form accessible to perception that improves our understanding of what factors and how exactly influenced this particular prediction and the operation of the model as a whole. This information can take different forms, for example, visualizations and graphs or text explanations.
Full version articles.


